SEO dünyası artık yalnızca arama motoru sonuç sayfalarındaki sıralamalardan ibaret değil. Büyük dil modelleri (LLM – Large Language Models), içerikleri tarıyor, analiz ediyor ve kullanıcıya doğrudan cevap üretiyor. Yapay zekâ destekli arama deneyimlerinin yaygınlaşmasıyla birlikte web sitesi sahipleri için yeni bir soru ortaya çıktı: İçeriklerimiz AI sistemleri tarafından nasıl kullanılıyor?
Bu noktada gündeme gelen kavramlardan biri llms.txt dosyasıdır. Henüz robots.txt kadar standartlaşmış olmasa da, yapay zekâ çağında içerik kontrolü ve veri yönetimi açısından stratejik öneme sahip bir yaklaşımı temsil eder.
Llms.txt Dosyası Nedir?
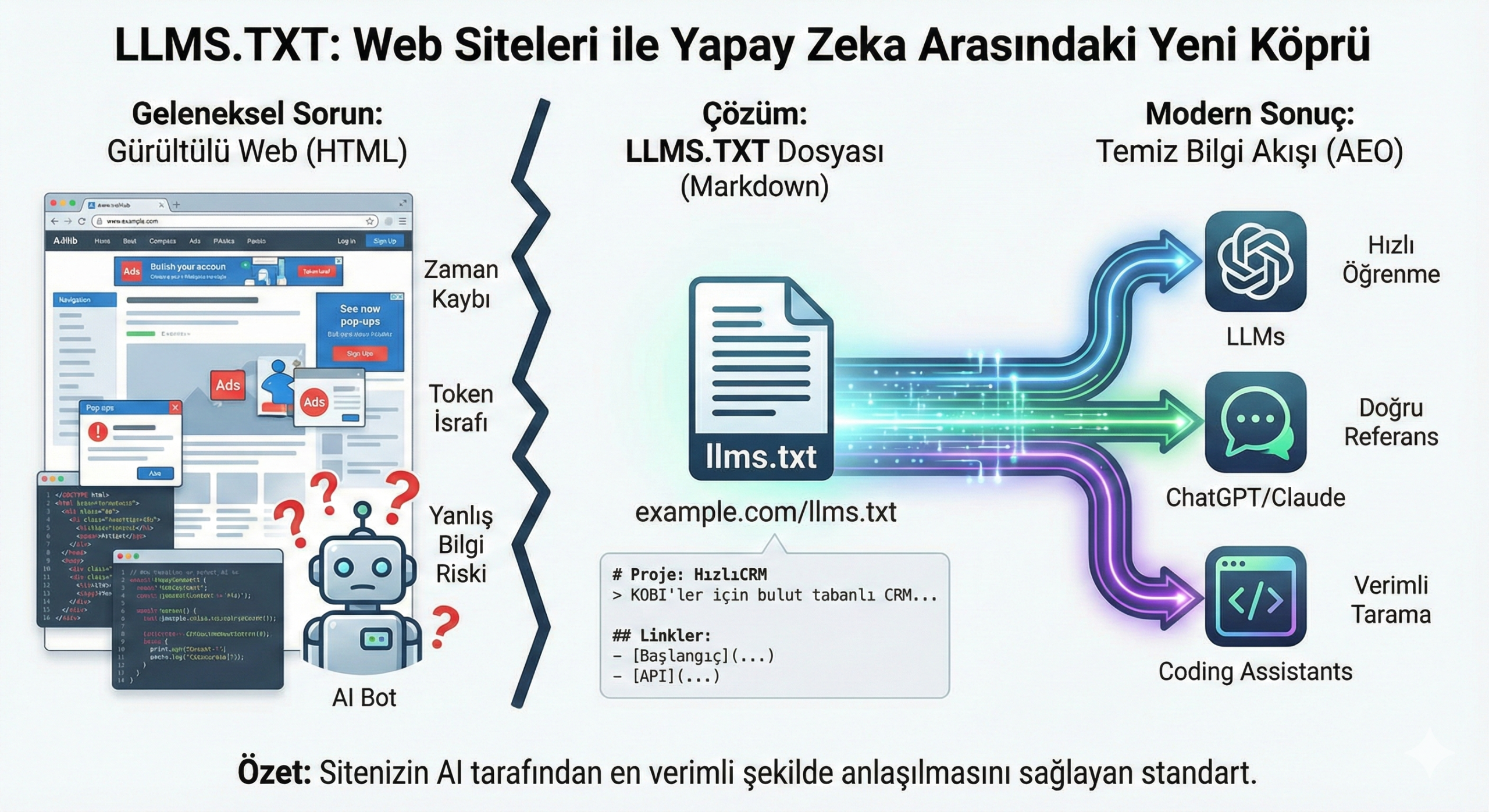
Llms.txt, web sitelerinin büyük dil modellerine içeriklerinin hangi koşullarda kullanılabileceğini belirtmeyi amaçlayan bir yapılandırma dosyasıdır.
Mantık olarak Robots Exclusion Protocol kapsamında kullanılan robots.txt dosyasına benzer bir düşünce yapısına dayanır; ancak hedef kitlesi klasik arama motoru botları değil, yapay zekâ modelleridir.
Bu dosya aracılığıyla teorik olarak şu konular hakkında yönlendirme yapılabilir:
- İçeriğin LLM’ler tarafından taranması
- Eğitim verisi olarak kullanılması
- Özetlenmesi veya cevap üretiminde referans alınması
- Belirli dizinlerin hariç tutulması
Henüz evrensel ve bağlayıcı bir standart olmadığı için uygulanabilirliği, ilgili AI sisteminin politikalarına bağlıdır.
Llms.txt Neden Ortaya Çıktı?
Üretken yapay zekâ sistemlerinin yaygınlaşmasıyla birlikte içerik üreticileri ve yayıncılar, veri kullanımı konusunda daha hassas hale geldi. Özellikle OpenAI, Google ve Microsoft gibi şirketlerin AI destekli arama ve sohbet sistemlerini yaygınlaştırması, içerik sahiplerinin kontrol talebini artırdı.
LLM’ler yalnızca sayfaları indekslemekle kalmıyor; içerikleri analiz ediyor, özetliyor ve bazen kullanıcıya kaynağa gitmeden doğrudan cevap sunabiliyor. Bu durum, özellikle reklam ve trafik odaklı gelir modeli olan siteler için yeni bir risk alanı oluşturuyor.
Llms.txt bu risk alanına karşı geliştirilen bir niyet beyanı olarak değerlendirilebilir.
Llms.txt Dosyası Ne İşe Yarar?
Llms.txt dosyasının ne işe yaradığını alt başlıklara ayırarak anlatmak daha mantıklı olacaktır. Bu bağlamda:
İçerik Kullanım Koşullarını Belirtme
Web siteleri, içeriklerinin yalnızca indekslenmesini, özetlenmesini ya da eğitim verisi olarak kullanılmasını sınırlamak isteyebilir. Llms.txt dosyası bu tercihi teknik olarak ifade etmeyi hedefler. Böylece içerik sahibi, yapay zekâ sistemlerine yönelik bir kullanım çerçevesi çizmeye çalışır.
AI Tabanlı Arama Görünürlüğünü Yönetme
AI destekli arama sistemleri klasik SERP yapısından farklı çalışır. Örneğin Bing ve Google, yapay zekâ destekli cevap alanları sunarak kullanıcıya özet bilgi verebilir. Bu yapı içinde içerik, doğrudan trafik üretmeyebilir ancak marka görünürlüğü sağlayabilir. Llms.txt, bu kullanımın sınırlarını belirleme amacı taşır.
Telif ve Veri Koruma Perspektifi
Özgün araştırma, akademik yayın veya veri yoğun içerik üreten siteler için AI modellerinin kontrolsüz veri kullanımı ticari risk doğurabilir. Llms.txt yaklaşımı, içerik haklarını koruma yönünde teknik bir pozisyon alma girişimidir.
Llms.txt ile Robots.txt Arasındaki Farklar
Robots.txt uzun yıllardır arama motorları tarafından kabul edilen ve uygulanan bir standarttır. Arama botlarına hangi dizinlerin taranabileceğini ya da taranamayacağını açıkça belirtir.
Llms.txt ise henüz resmi bir internet standardı değildir ve bağlayıcılığı yoktur. Robots.txt arama motoru indeksleme süreçlerine doğrudan etki ederken, llms.txt daha çok yapay zekâ modellerine yönelik bir politika bildirimi niteliği taşır. Uygulanıp uygulanmayacağı tamamen ilgili AI sağlayıcısının inisiyatifindedir.
SEO Açısından Gerçekten Önemli mi?
Bu sorunun cevabı, sitenin iş modeline göre değişir.
Eğer gelir modeli doğrudan organik trafiğe dayanıyorsa ve AI özetleri kullanıcıyı siteye yönlendirmeden cevap sunuyorsa, bu durum trafik kaybına yol açabilir. Böyle bir senaryoda llms.txt gibi kontrol mekanizmaları daha kritik hale gelir.
Ancak marka bilinirliği, otorite inşası ve referans gösterilme stratejisi öncelikliyse, AI sistemlerinde kaynak olarak yer almak görünürlük avantajı yaratabilir. Bu durumda tamamen engelleyici bir yaklaşım yerine kontrollü bir görünürlük stratejisi daha rasyonel olabilir.
Teknik Olarak Nasıl Konumlandırılır?
Henüz resmi bir RFC standardı olmadığı için kesin bir uygulama çerçevesi bulunmaz. Ancak teorik olarak:
- Dosya site kök dizinine eklenir (example.com/llms.txt).
- Belirli kullanım kuralları tanımlanır.
- AI botları için yönlendirme yapılır.
Örnek bir yapı şu şekilde olabilir:

Buradaki kritik nokta, bu kuralların teknik olarak yazılabilmesi değil; AI sisteminin bu kuralları dikkate alıp almamasıdır. Bu nedenle llms.txt, teknik bir bariyerden çok, politik ve stratejik bir duruş anlamına gelir.
LLM SEO ve Geleceğin Arama Deneyimi
Geleneksel SEO, arama motoru sonuçlarında üst sıralarda yer almayı hedefler. Ancak üretken arama sistemleriyle birlikte yeni bir kavram öne çıkıyor: Generative Engine Optimization (GEO).
Artık yalnızca sıralanmak değil, yapay zekâ tarafından üretilen cevapların içinde referans gösterilmek de önem kazanıyor. Bu dönüşüm, içerik stratejisini daha yapılandırılmış veri, daha net otorite sinyalleri ve daha güvenilir kaynak üretimi üzerine kurmayı gerektiriyor.
Llms.txt bu dönüşümün savunma tarafında yer alırken, büyüme tarafı güçlü içerik mimarisi, semantik bütünlük ve marka güveni üzerinden şekilleniyor.
Llms.txt dosyası, yapay zekâ destekli içerik tüketiminin yükselişiyle ortaya çıkan yeni bir kontrol yaklaşımıdır. Henüz resmi ve bağlayıcı bir standart değildir; ancak AI arama sistemlerinin yaygınlaşmasıyla birlikte daha fazla önem kazanması beklenmektedir.
Bu dosya tek başına bir SEO çözümü değildir. Asıl mesele, yapay zekâ çağında içerik görünürlüğünü nasıl yöneteceğinizdir. Kimi projelerde korumacı bir yaklaşım tercih edilebilirken, kimi projelerde AI sistemlerinde referans olmak stratejik bir avantaj sağlayabilir.
Llms.txt İşlemi Sonrasında Gelen İstekleri Takip Etmek Neden Önemlidir?
Llms.txt dosyasını yayınlamak tek başına yeterli değildir. Asıl kritik nokta, bu dosya sonrası sitenize gelen bot ve AI kaynaklı isteklerin düzenli olarak analiz edilmesidir. Çünkü teknik bir kural tanımlamak ile o kuralın gerçekten dikkate alınıp alınmadığını görmek iki farklı süreçtir.
AI çağında SEO yalnızca görünürlük değil, veri akışını yönetme disiplinidir.
Gerçekten Hangi Botlar Sitenizi Tarıyor?
Llms.txt ekledikten sonra ilk yapılması gereken şey, server log analizidir. Çünkü birçok AI sistemi, kendini açıkça tanımlayarak tarama yapmaz.
Log kayıtları sayesinde şunlar analiz edilebilir:
- User-Agent bilgileri
- IP blokları
- Tarama sıklığı
- Hangi dizinlere erişildiği
- Hangi dosyaların indirildiği
Bu analiz, teorik kontrol ile pratik veri kullanımını karşılaştırmanızı sağlar. Eğer llms.txt ile sınırlandırdığınız bir dizine hâlâ yoğun erişim varsa, dosyanın dikkate alınmadığını anlayabilirsiniz.
Eğitim Verisi Amaçlı Yoğun Veri Çekimi Tespiti
Bazı AI sistemleri klasik arama motoru botları gibi hafif crawl yapmaz; sayfaların tam HTML çıktısını ve içerik bloklarını toplu şekilde çekebilir.
Şu sinyaller kritik kabul edilir:
- Kısa sürede yüksek sayfa isteği
- Pagination yapılarının agresif taranması
- Arşiv sayfalarının sistematik çekilmesi
- Eski içeriklerin yoğun şekilde indirilmesi
Bu tip davranışlar, indeksleme değil veri toplama amaçlı olabilir. Takip mekanizması olmadan bunu fark etmek mümkün değildir.
Crawl Budget ve Sunucu Performansı
Yoğun AI taramaları, özellikle içerik zengini sitelerde sunucu yükünü artırabilir. Bu durum:
- Gerçek kullanıcı deneyimini olumsuz etkileyebilir
- Googlebot’un crawl bütçesini dolaylı olarak etkileyebilir
- TTFB ve Core Web Vitals metriklerini bozabilir
Llms.txt yayınladıktan sonra bot trafiğini ölçmek, teknik SEO sağlığını korumak açısından önemlidir.
Trafik Kaybı ile AI Görünürlüğü Arasındaki Denge
AI sistemleri içeriğinizi özetleyip kullanıcıya doğrudan cevap sunuyorsa, organik tıklamalar azalabilir. Bu durumda şu metriklerin birlikte analiz edilmesi gerekir:
- Organik trafik düşüşü
- Gösterim artışı
- Brand query artışı
- Referral trafiği
Eğer gösterimler artıyor ama tıklamalar düşüyorsa, içerik AI cevap alanlarında kullanılıyor olabilir. Bu dengeyi ölçmeden strateji belirlemek risklidir.
Güvenlik ve Veri Koruma Perspektifi
Log takibi yalnızca SEO açısından değil, güvenlik açısından da önemlidir. Özellikle:
- Kimliği belirsiz botlar
- Proxy üzerinden gelen istekler
- Sürekli IP değiştiren taramalar
Bu tür aktiviteler, yalnızca AI taraması değil veri scraping veya içerik kopyalama girişimi de olabilir. Llms.txt yayınlandıktan sonra artan bilinmeyen bot trafiği dikkatle izlenmelidir.
Stratejik Karar Alabilmek İçin Veri Gereklidir
Llms.txt dosyasını ekledikten sonra iki farklı yol izlenebilir:
- Koruyucu yaklaşım: AI erişimini sınırlandırmak
- Görünürlük odaklı yaklaşım: AI sistemlerinde referans olmayı hedeflemek
Hangi yaklaşımın doğru olduğuna karar verebilmek için ölçüm şarttır. Bot logları, trafik değişimleri ve indeksleme verileri birlikte analiz edilmeden sağlıklı bir strateji oluşturulamaz.
Hangi Araçlarla Takip Edilebilir?
Takip süreci şu araçlarla yürütülebilir:
- Sunucu log analizi (Apache / Nginx logları)
- CDN logları (Cloudflare vb.)
- Google Search Console karşılaştırmalı performans raporları
- Web analitik araçları
Bu veriler birlikte değerlendirildiğinde, AI sistemlerinin içerik üzerindeki etkisi daha net anlaşılır.
Önümüzdeki dönemde SEO, yalnızca indekslenme ve sıralama değil; cevap üretim ekosisteminde yer alma mücadelesine dönüşecektir. Llms.txt ise bu dönüşümün erken dönem araçlarından biri olarak konumlanmaktadır.

